
Google has released DiffusionGemma, an open-source experimental model that disrupts the conventional token-by-token generation paradigm by generating 256 tokens in parallel with each forward pass. In real-world tests on H100 GPUs, it achieves over 1,000 tokens per second, delivering up to a fourfold speedup. The model activates only 3.8 billion parameters and, when quantized, can run on consumer-grade GPUs with 18GB of VRAM, offering developers a new technical pathway for low-latency, local workflow scenarios.
Google has released DiffusionGemma, an open-source experimental model leveraging text diffusion technology, achieving up to a fourfold acceleration in text generation on dedicated GPUs and offering developers a new technical pathway for low-latency local workflows.
This model is built upon Google’s Gemma 4 series architecture and the research outcomes from Gemini Diffusion, and is released as open source under the Apache 2.0 license.
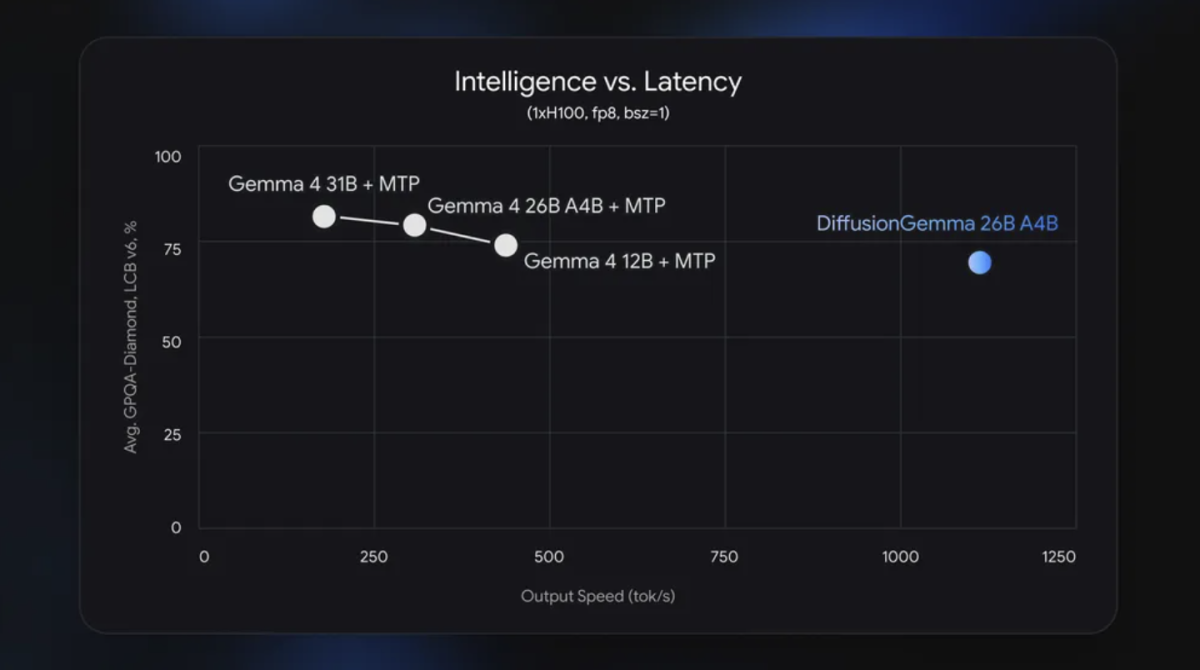
 Unlike traditional autoregressive large language models that generate text token by token, DiffusionGemma can generate 256 tokens in parallel per forward pass, achieving measured output speeds exceeding 1,000 tokens per second on a single NVIDIA H100 and over 700 tokens per second on an NVIDIA GeForce RTX 5090.
Unlike traditional autoregressive large language models that generate text token by token, DiffusionGemma can generate 256 tokens in parallel per forward pass, achieving measured output speeds exceeding 1,000 tokens per second on a single NVIDIA H100 and over 700 tokens per second on an NVIDIA GeForce RTX 5090.
Google also noted that DiffusionGemma remains experimental and currently delivers lower overall output quality compared to the standard Gemma 4 model. For production applications requiring the highest-quality outputs, Google recommends continuing to deploy the standard Gemma 4.
Architectural Innovation: From 'Typewriter' to 'Printing Press'
The core technical breakthrough of DiffusionGemma lies in its reimagined approach to how language models utilize hardware.
Traditional language models operate like typewriters, generating text sequentially from left to right. While this mechanism remains reasonably efficient on cloud servers—where thousands of user requests can be batched together to share computational resources—it leads to significant GPU underutilization in single-user local environments, as the hardware spends most of its time idle waiting between token generations.
DiffusionGemma employs a text diffusion approach, shifting the primary bottleneck from memory bandwidth to compute capacity.
The model first generates a set of random placeholder tokens on a 'canvas,' then iteratively refines them over multiple rounds—locking in confirmed tokens at each step and using them as contextual cues to revise the remaining content until convergence into a complete paragraph. Google likens this process to 'upgrading from a single typewriter to a large-scale printing press capable of printing an entire page of text simultaneously.'
Notably, this speed advantage comes with clear boundaries of applicability. Google states that in high-concurrency cloud service scenarios, autoregressive models can fully leverage computational resources through batch processing, diminishing the relative benefit of DiffusionGemma’s parallel decoding—and potentially increasing service costs. Its throughput advantage is primarily evident in low-to-moderate batch-size scenarios on a single accelerator.
Low hardware deployment barrier, supporting bidirectional attention and self-correction
DiffusionGemma is a 26-billion-parameter mixture-of-experts (MoE) model, but only 3.8 billion parameters are activated during inference. After quantization, the model can run on consumer-grade high-end GPUs with 18GB of VRAM, lowering the hardware barrier for local deployment.
Functionally, the model supports a bidirectional attention mechanism, enabling each token to attend to all other tokens within the same segment during generation. Google considers this feature particularly advantageous for non-linear generation tasks, including in-line editing, code completion, amino acid sequence generation, and mathematical diagram construction.
The model also features intelligent self-correction capabilities, allowing it to evaluate and revise entire text segments in real time during output generation.
Third-party AI tools company Unsloth fine-tuned DiffusionGemma and successfully enabled it to solve Sudoku puzzles—a task requiring lookahead reasoning that poses challenges for traditional autoregressive models. DiffusionGemma’s bidirectional attention mechanism makes handling such tasks more natural.

Positioning and Limitations: Experimental Exploration, Not a Production Replacement
Google explicitly positions DiffusionGemma for researchers and developers rather than as a direct replacement for existing production models. Its target use cases focus on latency-sensitive local interactive workflows, such as real-time text editing, rapid content iteration, and non-linear text structure generation.
Despite its significant speed advantage, Google acknowledges that DiffusionGemma still lags behind the standard Gemma 4 in output quality and exhibits a clear trade-off between capability dimensions in benchmark evaluations. This implies that, for commercial applications requiring high-precision outputs, the model currently does not meet the threshold to replace mainstream models.
Text diffusion techniques themselves are not a new concept; the AI research community has explored them for years. However, applying them to large-scale models has long posed significant challenges.
The release of DiffusionGemma marks a measurable step by Google toward practical implementation of this research direction. Whether it can achieve a better balance between quality and speed will remain a key focus for market observers.
Editor/Liam