
① On the Artificial Analysis comprehensive benchmark, GLM-5.2 scored 51 points, achieving state-of-the-art (SOTA) performance among open-source models; ② It is expected that after the Ascend 950 super-node launches in the second half of the year, it will become a key computing infrastructure for GLM-5.2.
June 17 (Reporter Li Mingming) — Zhipu AI released and open-sourced its new flagship large model, GLM-5.2, on June 17.
On the Artificial Analysis comprehensive benchmark, GLM-5.2 scored 51 points, achieving state-of-the-art (SOTA) performance among open-source models.
 According to Zhipu AI’s briefing to a reporter from The China Science & Technology Daily, this is its most capable open-source model to date, with core advancements focused on two key areas: transforming the 1M-token context window from a theoretical specification into a production-ready capability, and further enhancing long-horizon coding capabilities.
According to Zhipu AI’s briefing to a reporter from The China Science & Technology Daily, this is its most capable open-source model to date, with core advancements focused on two key areas: transforming the 1M-token context window from a theoretical specification into a production-ready capability, and further enhancing long-horizon coding capabilities.
A reporter from The China Science & Technology Daily conducted an immediate multi-hour continuous real-world test of GLM-5.2 Max, covering scenarios such as long-context retrieval and generation, Long Horizon agent-based coding, and end-to-end delivery of a complex industry research workflow involving nearly one million tokens in a single run.
Real-world testing of GLM-5.2
According to Zhipu AI, the core breakthrough of GLM-5.2 lies in making the million-token context window engineering-ready.
For example, the model can process over 880,000 tokens in a single continuous task, autonomously completing the entire software delivery pipeline—from development, integration, and testing to packaging and deployment—within a few hours, producing a fully functional application spanning web, mobile, and mini-program platforms. Previously, engineering tasks of similar scale typically required a team working collaboratively for several weeks.
While many models on the market today support million-token contexts, it is an open secret that numerous models begin to 'lose information' beyond 300,000 tokens, resulting in a sharp drop in reasoning quality over long texts. Zhipu AI’s technical approach combines several innovations at the attention mechanism level: KV8 quantization, LayerSplit, IndexShare-4, and HiSparse sparse attention.
From an engineering perspective, these modifications have a clear objective: minimizing both performance degradation and inference cost at the 1M-token length. According to official data from Zhipu AI, at a 1M-token context length, the FLOPs per token are reduced to 2.9× that of conventional approaches—representing approximately a 66% reduction in computational load.
Zhipu disclosed a real-world test result of the model in its technical blog: the model completed, in a single pass, the full application development and delivery covering web, mobile, and mini-programs, processing a total of 880,000 tokens—nearly exhausting its 1M-token context window. This demonstrates that in real-world, ultra-long engineering tasks, the model can maintain complete project state continuity, rather than forgetting constraints established as early as the third round by the tenth round of conversation.
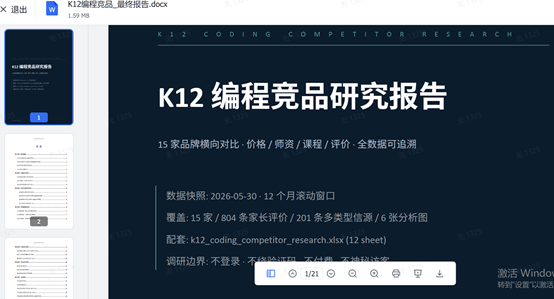
A reporter from The Science and Technology Innovation Board Daily also conducted a hands-on test of GLM-5.2, assigning it a task to perform an in-depth competitive analysis of K12 online programming education platforms based on massive publicly available materials. The task required horizontal coverage of 15 leading brands in the sector, with dissection across four core dimensions—curriculum, teaching staff, pricing, and parent reviews—and demanded a comprehensive deliverable package including an XLSX database with source citations, a 20-page PDF analytical report, six visual comparison charts, and reusable data-processing scripts.
After approximately half an hour, the model successfully retained all 804 parent reviews and output a standardized Excel file containing 12 data subtables, a complete industry report, and executable scripts. Throughout the process, it avoided common issues associated with long-context models, such as brand confusion, loss of data dimensions, or inconsistent statistical methodologies. However, extreme scenarios approaching the full 1M-context limit still present room for optimization.

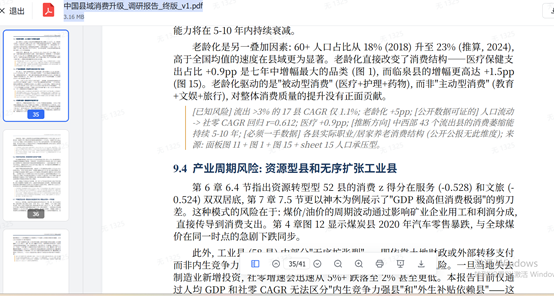
To further validate the model’s deep analytical research capabilities, a reporter from The Science and Technology Innovation Board Daily issued another practical instruction: conduct a systematic study of county-level consumption upgrading in China from 2018 to 2024 using macroeconomic data from the National Bureau of Statistics and other publicly verifiable sources, and build a traceable database covering over 200 counties, delivering the raw data tables, a research report, a presentation deck, and accompanying visualizations.
The test revealed that GLM-5.2 Max can ingest nearly one million tokens of macroeconomic data in a single round and fully deliver an end-to-end solution—including a quantitative database spanning more than 400 counties nationwide, a deep-dive analytical report, and a complete set of visual charts—making it well-suited for financial consulting-grade, long-cycle big-data research tasks.
So, how does GLM-5.2’s programming capability position itself among the world’s top-tier models?
Zhang Youyu, Secretary-General of the AI Special Committee of the Beijing Computer Society and Adjunct Researcher at Peking University, told a reporter from The Science and Technology Innovation Board Daily that the release of Zhipu’s GLM-5.2 marks a critical breakthrough for domestic large models in programming-specific scenarios.
First, it breaks the duopoly, as GLM-5.2 demonstrates significant advantages in long-context programming scenarios thanks to its benchmark-topping real-world performance and high cost-effectiveness, reshaping the industry landscape and giving rise to a new ‘Big Three’ consisting of Zhipu, OpenAI, and Anthropic.
Second, although it has not yet achieved comprehensive superiority across all dimensions, the model is already a viable alternative to leading overseas models in most medium- to high-frequency real-world development scenarios. ‘However, key weaknesses remain: compared with the global frontier, GLM-5.2 still exhibits a technological gap in deep mathematical-logical reasoning and the complex integration of cross-domain knowledge—areas that require focused advancement in the next phase.’
Day 0 Compatibility with Domestic AI Accelerators
Beyond performance, GLM-5.2 is released under the most permissive MIT license, allowing free commercial use, and its training and online inference do not rely on overseas computing resources.
On its launch day, GLM-5.2 completed inference compatibility with eight major domestic computing platforms on Day 0. This combination of 'open-source domestic model + domestic computing power' has drawn industry attention.
Zhipu AI also told reporters from The Science and Technology Innovation Board Daily that it expects the Ascend 950 super-node, scheduled for release in the second half of the year, to become a key computing infrastructure for GLM-5.2.
"Day 0 compatibility" does not merely mean the model "can run on domestic chips," but rather that deep inference optimization and operator-level tuning were already completed on the day of release—indicating that domestic chips are no longer treated as a "backup option," but as a first-tier infrastructure on par with overseas computing platforms.
Zhipu’s compatibility list covers leading domestic computing companies: Huawei Ascend, Cambricon, Moore Threads, Hygon, Biren, MetaX, Kunlunxin, and Pingtouge. This approach aims both to diversify supply chain risk and to maximize reach across various sectors’ demand for domestic alternatives.
From a business perspective, GPU procurement and leasing currently account for the majority of large-model companies’ computing costs in China, with heavy reliance on NVIDIA’s H100/H200 and other high-end overseas chips. Against the backdrop of escalating U.S.-China technological competition, achieving self-reliance and control over the computing supply chain has shifted from a "strategic reserve" to a "survival necessity."
From a developer’s standpoint, compatibility with domestic computing platforms means two things: first, enterprise users can deploy GLM-5.2 in a fully domestic environment to meet data security and compliance requirements; second, when overseas computing supply becomes volatile, a mature domestic alternative is already available, eliminating the need to start adaptation from scratch.
Technically speaking, achieving inference compatibility across multiple domestically developed chips with significantly different architectures requires extensive engineering optimizations in operator compatibility, memory management, and inference efficiency. Zhipu’s ability to deliver synchronized Day 0 compatibility demonstrates that its core engineering team has accumulated substantial expertise in heterogeneous computing.