
來源:字母AI
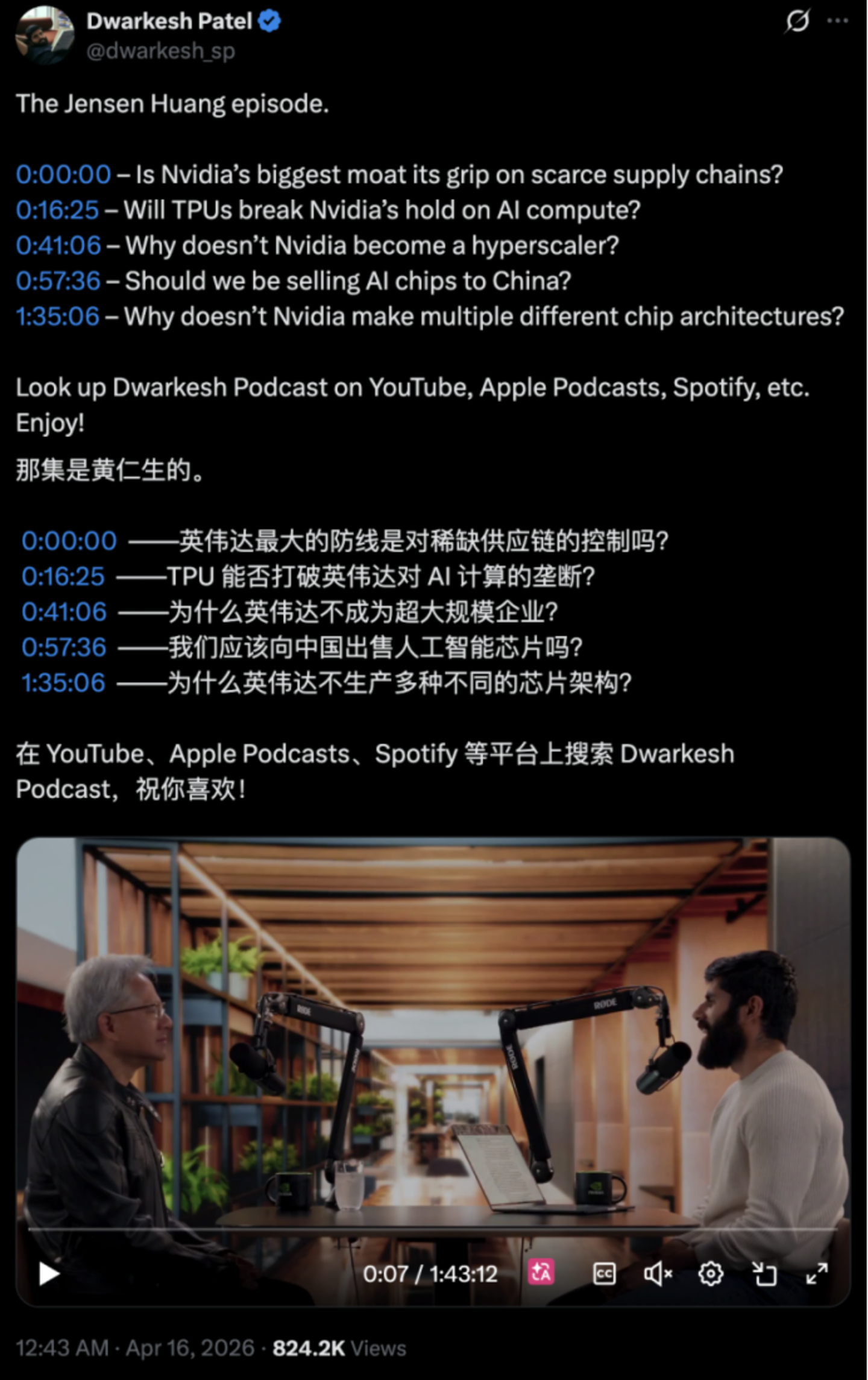
近日, $英偉達 (NVDA.US)$ CEO黃仁勳接受了知名科技主持人Dwarkesh Patel的專訪,長達1小時45分鐘。
這位油管百萬大V以遞進式的提問方式和極其鋒利的選題而出名,這次也不例外地選擇了直白開場,一上來就直戳英偉達的「肺管子」,問黃仁勳:「如果軟件被商品化了,那英偉達會不會也被商品化?」
 有網友評價這次訪談:很少見黃仁勳這麼「生氣」。
有網友評價這次訪談:很少見黃仁勳這麼「生氣」。
在這次訪談中,黃仁勳深度回答了關於AI時代的競爭本質、英偉達如何鎖住供應鏈、爲什麼不做AI雲,以及中國與AI芯片等問題。
我們整理了這次訪談,內容亮點都在下面。
英偉達真正的護城河不是芯片,是供應鏈
Dwarkesh:現在市場上有一種看法是,AI會讓軟件逐漸商品化,很多軟件公司的估值已經因此下滑了。
從一個可能比較天真的角度來看:你們把設計交給晶圓廠,比如把GDS文件交給 $台積電 (TSM.US)$ ,再由他們製造芯片,然後再和像SK Hynix、Micron、Samsung做的HBM封裝在一起,最後送到ODM廠組裝成整機。
所以本質上,英偉達做的是軟件,只不過由別人來製造。如果軟件被商品化了,那英偉達會不會也被商品化?
黃仁勳:歸根結底,總有一件事必須發生:把電子變成Token。不僅僅是變成Token,還要讓這些Token越來越有價值。我認爲這件事很難被完全商品化。
把電子轉化爲Token本身就是一段非常複雜的旅程,就像讓一個分子比另一個分子更有價值一樣,這裏麪包含了大量的藝術、工程、科學和發明。我們現在正在親眼見證這一切發生,而這個過程遠沒有被完全理解,也遠沒有結束。所以我不認爲它會被商品化——當然,我們會讓這個過程變得更高效。
如果用剛才的方式來理解英偉達,已經接近我對公司的心智模型了:輸入是電子,輸出是Token,中間就是英偉達。我們的工作是用盡可能少的東西,完成這個轉化過程,並把能力做到極致。
所謂「儘可能少」,意思是能不做的事情,我們就不做。我們會把這些事情交給合作伙伴,讓它成爲整個生態的一部分。如果你看今天的英偉達,我們在上下游都有極其龐大的合作生態,所以我們儘量少做,但我們必須做的那一部分是極其困難的。我不認爲這部分會被商品化。
Dwarkesh:那企業軟件公司呢?很多人覺得它們會被AI衝擊。
黃仁勳:現在很多軟件公司,本質上是「工具製造商」。比如Excel、PowerPoint,或者像Cadence、Synopsys。當然也有一些是流程系統,但很大一部分是工具。但我看到的趨勢是完全相反的:未來Agent的數量會指數級增長,使用這些工具的用戶也會指數級增長。也就是說工具的使用量,會暴漲。
舉個例子:像Synopsys Design Compiler這種工具,未來它的實際用量很可能會暴漲。今天我們被工程師數量限制住了,但未來,每個工程師都會有一堆Agent輔助。這些Agent會去探索設計空間,探索的程度會遠遠超過今天。而它們會用的,正是今天這些工具。
所以我認爲工具的使用量,會推動這些軟件公司的增長,而不是壓垮它們。這件事之所以現在還沒有發生,是因爲Agent還不夠會用工具。接下來會發生兩件事:要麼這些軟件公司自己去做Agent;要麼Agent變得足夠強大,可以使用這些工具。最終很可能是兩者同時發生。
Dwarkesh:在你們最近的業績裏,我看到英偉達已經有接近1000億美元的採購承諾,還有分析認爲這個數字可能會達到2500億美元。有一種解讀是這樣的:英偉達的護城河在於你們鎖定了未來幾年關鍵的稀缺資源,比如晶圓、內存、封裝。別人即使有芯片設計能力,也不一定能拿到這些資源。這是你們未來幾年的核心優勢嗎?
黃仁勳:這是我們能做到、但別人不太容易做到的一件事情。原因其實很簡單:我們之所以能在上游做出這麼大的承諾,是因爲我們有能力把這些產能買下來,並且賣出去。
那些承諾有些是顯性的,比如我們直接籤的採購合同;但也有很多是隱性的,比如我們的供應鏈夥伴會自己去做投資。因爲我會和他們的CEO溝通,我會告訴他們這個行業會變多大、爲什麼會變大、我們是如何推理出來的。在這個過程中,我其實是在對齊整個上游生態的認知。
那爲什麼他們願意爲我們投資,而不是爲別人?原因很簡單:他們知道我有能力把他們的產能買下來,並賣給下游。英偉達的下游需求非常大,正是因爲有這種下游需求的規模,才讓他們願意在上游投入。
如果你去看GTC大會,你會發現很多人對它的規模感到驚訝。這是一個360度的AI生態,整個AI世界的人都在一個地方,而他們來這裏,是因爲他們需要彼此。上游需要看到下游,下游需要看到上游。他們也需要看到AI的發展,以及那些AI原生公司和創業公司。
我花了很多時間,不斷去告知和影響我們的供應鏈和生態夥伴,讓他們理解機會是什麼、爲什麼會發生、什麼時候會發生、規模會有多大。很多人會覺得我的Keynote有點像上課,甚至有點折磨,但這是故意的。因爲我需要讓整個生態,像我一樣去理解未來。
沒有任何一個瓶頸,會持續超過2到3年
Dwarkesh:我想更具體地理解一個問題:上游供應鏈真的能跟得上嗎?你們過去幾年基本是收入翻倍增長,同時提供給全球的算力也在大幅增長。現在這個規模已經很大了,比如你們是TSMC先進製程(N3、N2)的最大客戶之一,甚至有分析說,今年AI會佔到N3產能的60%,明年可能到80%以上。
那問題來了,如果你已經是最大客戶了,你還怎麼繼續「翻倍」?這個增長會不會被上游限制住?
黃仁勳:在某一個時間點上,需求超過供給,是很正常的事情——甚至,這是一種好狀態。你希望一個行業的即時需求是大於總供給的。當然,也可能會在某一個具體環節被卡住,比如說,有時候真的會被「水管工」卡住(笑)。
Dwarkesh:水管工?
黃仁勳:對,真的。你可能在某個時間點,被某個完全意想不到的環節限制住。但這並不是壞事,因爲當某一個瓶頸出現的時候,整個行業會迅速「圍攻」它。
舉個例子:前幾年大家一直在討論CoWoS,但現在你已經很少聽到有人談這個問題了。因爲過去兩年,整個行業對它進行了極端投入,連續擴產,現在基本已經解決了。TSMC現在也已經意識到,CoWoS的供給必須和邏輯芯片和內存的需求同步擴展。以前,CoWoS和HBM是「特殊技術」,但現在已經不是了,它們已經變成了主流計算的一部分。
我們現在比以前更有能力去影響更大範圍的供應鏈。我現在說的這些其實5年前我就已經在說了,有些公司當時相信並且投資了,比如Micron,我還記得當時和他們CEO的那次會面,我當時非常明確地告訴他們,未來會發生什麼、爲什麼會發生。他們當時真的投入了,而且投入得很深。從LPDDR到HBM,他們都做了很多投資,結果當然也非常好。有些公司後來才跟上,但現在大家基本都已經在這個節奏裏了。
所以我的看法是:沒有任何一個瓶頸,會持續超過兩到三年,每一代都會有新的瓶頸,但也都會被解決。現在大家已經開始提前幾年去預判這些瓶頸,並提前投資。比如硅光(silicon photonics),比如新的封裝技術、新的測試設備……我們在過去幾年做了很多這樣的事情,本質上是在「重塑供應鏈」,讓它爲未來的規模做好準備。
Dwarkesh:聽起來有些瓶頸比其他更容易擴展,比如CoWoS和封裝可以擴,但有些東西,比如製造能力本身,可能更難。
黃仁勳:我剛才其實已經說到最難的那個了:水管工,還有電工。這是最難擴展的。
這也是爲什麼我對現在很多末日論者「AI會終結工作」的說法感到擔憂。如果我們去勸年輕人不要做軟件工程師,那未來我們就會缺軟件工程師。10年前,有人說「千萬不要做放射科醫生」,說這是第一個會被AI取代的職業,這些視頻現在網上還能找到。結果呢?我們現在缺放射科醫生。
Dwarkesh:回到剛才的問題,製造能力這邊,你如何讓晶圓產能每年翻倍?如何讓EUV設備每年翻倍?
黃仁勳:這些都不是問題,它們都可以在2到3年內擴展。關鍵只有一個,那就是需求信號(demand signal)。一旦有明確的需求,能做1台,就能做10台;能做10台,就能做100萬台……這些東西並不難複製。
Dwarkesh:那你會不會直接去跟ASML說:「未來三年我們需要更多EUV機器」?
黃仁勳:有些事情我會直接做,有些是間接做。如果我能說服TSMC,那ASML自然也會被說服,所以要找到真正的關鍵節點。但這些都不讓我擔心——真正讓我擔心的是能源,你不可能在沒有能源的情況下建立一個新產業。無論是想重建制造業、建AI工廠、做電動車、做機器人,這些都需要能源,而能源是一個長期問題。相比之下,芯片產能和封裝只是2到3年的問題。
Dwarkesh:我聽過一些完全相反的說法,所以我不確定該相信誰(笑)。
黃仁勳:你現在是在跟專家對話(笑)。
AI只是計算的一部分,而計算遠不止AI
Dwarkesh:我想再回到競爭問題,比如Google TPU。現在世界上最強的模型裏,有相當一部分是在TPU上訓練的,這對英偉達意味着什麼?
黃仁勳:我們做的東西是完全不同的。英偉達做的是加速計算(accelerated computing),而不是一個「張量處理單元」。加速計算被用在各種各樣的領域,比如分子動力學、數據處理、流體力學……當然,也包括AI。
AI現在是最熱門的討論方向,但計算遠不止AI。我們做的是重新發明計算方式,從通用計算走向加速計算。我們的覆蓋範圍比任何TPU都要大得多,因爲我們可以加速所有應用。
Dwarkesh:但現實情況是,你們現在的收入絕大多數還是來自AI,而不是來自藥物發現或者量子計算。而AI的核心計算,很多人認爲就是矩陣乘法。TPU在這方面是高度優化的,雖然GPU更通用。那問題是,對於當前這波AI需求來說,TPU是不是更適合?
黃仁勳:矩陣乘法確實很重要,但它不是全部。如果你想發明新的attention機制,想用不同方式做計算分解,或者想設計全新的模型架構,比如混合SSM模型,融合diffusion和autoregressive模型……你需要的是一個完全可編程的系統。
AI進步的核心是算法。摩爾定律大概每年提升25%,但我們卻在實現10倍甚至100倍的提升。這些提升來自新的算法、新的模型結構、新的計算方式,而如果沒有可編程性,你甚至不知道從哪裏開始做這些創新。
Dwarkesh:那我們聊一個更現實的問題。你的客戶,比如Amazon、Google、Microsoft,他們有能力寫自己的kernel,甚至做自己的軟件棧。那CUDA還重要嗎?
黃仁勳:CUDA是一個非常豐富的生態系統。如果你要開發系統,從CUDA開始是非常合理的。我們支持所有框架,如果你要寫自定義kernel也可以。我們甚至在Triton裏投入了大量技術。
但你要考慮,當系統出問題時,是你的代碼有問題,還是底層系統有問題?你當然會希望問題出在你自己這裏,CUDA的價值就在於,你可以信任底層。
另外一個關鍵點是安裝基數(install base),作爲開發者,你最想要的是你的軟件可以運行在大量機器上。我們現在有數億GPU,在所有云平台上,各種型號,各種規模。這意味着,你開發一次,就可以在全世界運行。
Dwarkesh:但如果你的主要客戶是這些超大公司,他們完全可以爲自己的系統優化,甚至支持多個硬件平台。你的優勢還成立嗎?
黃仁勳:我們有大量工程師直接和這些AI公司合作。而且你要理解,GPU不是CPU:CPU就像一輛巡航車,誰都能開;但GPU更像F1賽車,你可以開,但要開到極限,需要專業能力。我們用大量AI來優化kernel,很多時候,我們幫客戶優化之後,性能提升2倍,有時候3倍……哪怕提升50%都是巨大的。而對於一個擁有巨大算力集群的公司來說,性能提升,直接意味着收入提升。
Dwarkesh:如果這些客戶可以自己做優化,競爭是不是會變成誰的價格更低、性能更高?
黃仁勳:我們在這些AI實驗室裏有大量工程師在幫他們優化,沒有人比我們更了解我們的架構。GPU不像CPU那樣完全通用,它更復雜,我們可以幫他們從系統裏再挖出2倍性能。而且我們的系統,在整個行業裏擁有最好的TCO(總擁有成本),沒有任何一家公司可以證明自己在TCO上比我們更好,無論是訓練還是推理。
Dwarkesh:但還是有公司在用其他方案。比如Anthropic最近宣佈和Broadcom以及Google合作,很多計算在TPU上。
黃仁勳:這是一個非常特殊的例子。如果沒有Anthropic,TPU的增長几乎不存在,他們是一個極端案例。
Dwarkesh:但OpenAI也在和AMD合作,甚至在做自己的芯片。
黃仁勳:但他們絕大多數計算還是在英偉達上,我們也會繼續和他們合作。我不介意別人嘗試其他方案。如果他們不嘗試,怎麼知道我們有多好?我們必須持續證明自己。
你看看歷史上那些做ASIC的項目,有多少最後是做不下去、被砍掉的。做一個比英偉達更好的系統並不容易。
Dwarkesh:他們的邏輯是不需要比你更好,只要不比你差太多,但成本更低就可以。
黃仁勳:ASIC的利潤率其實也很高,大概是65%,英偉達是70%。差距沒有你想的那麼大。
Dwarkesh:那回到一個問題,爲什麼英偉達沒有更早投資這些AI公司?
黃仁勳:我們在能做的時候,就做了。在更早的時候,我們沒有能力做那種級別的投資(幾十億美元),那在當時不是我們的模式。
而且我當時沒有意識到,這些公司其實沒有其他融資路徑——我當時以爲他們可以像普通公司一樣去找VC(風險投資)融資,但後來我才意識到,他們要做的事情,VC根本投不了。這是我的誤判。
Dwarkesh:現在你們有大量現金。爲什麼不自己做雲?成爲像AWS那樣的公司?
黃仁勳:這是我們的公司哲學:做必須做的事情,儘量少做其他事情。如果我們不做某件事,這個世界就不會有,那我們就必須做。但云這件事,如果我們不做,會有很多公司來做。所以我們不做。
對中國的態度:算法才是關鍵
Dwarkesh:很多分析認爲,中國在先進製程上落後。比如他們很多還是在7nm,沒有EUV設備。在算力上,有人估算,他們大概只有美國的十分之一,在HBM帶寬上,差距可能接近一個數量級。那是不是意味着美國可以先達到這些能力,先部署,先修補漏洞,從而獲得安全優勢?
黃仁勳:如果你要讓這個邏輯成立,那你必須假設他們沒有算力,但這不是現實。他們已經有大量算力。中國是全球第二大計算市場,如果他們願意集中資源,他們完全可以聚合足夠的算力。
Dwarkesh:但他們在帶寬、內存等方面還是落後。
黃仁勳:那他們就用更多芯片。AI本質上是並行計算問題。如果你有足夠的能源,你可以用更多節點來彌補差距。他們有大量能源,他們有很多已經建好的數據中心,甚至有空置的。他們可以用更多芯片,把系統拼起來,而且他們的芯片製造能力本身就很強。所以「他們沒有AI芯片」這個說法是錯誤的。
Dwarkesh:但先進芯片確實存在差距,比如帶寬差距可能接近一個數量級。
黃仁勳:那他們就用更多節點連接起來。就像我們用NVLink一樣,他們也已經在做類似的事情。比如華爲,他們已經在把大量計算節點連接成一個系統,通過硅光(silicon photonics)等技術把大量計算資源連接在一起。所以如果你只看單個芯片,你會低估整個系統。
而且不要忘了,算法才是關鍵。他們有大量優秀研究者,這才是他們最大的優勢。很多AI進步來自算法,而不是硬件。如果你在算力上受限,你反而會被逼去做更好的算法,比如DeepSeek——這不是一個無關緊要的進展。它代表的是一種能力:在算力受限的情況下,依然能做出非常強的模型。
Dwarkesh:那如果DeepSeek這樣的模型在華爲芯片上首先優化、首先跑起來呢?
黃仁勳:那就是一個很糟糕的結果。如果一個強大的模型,在非美國技術棧上運行得更好,那對美國來說是壞消息。
即使沒有AI,英偉達也會是一個非常大的公司
Dwarkesh:剛才我們在討論TSMC和內存這些瓶頸。那如果未來是這樣一個世界:你們已經佔據了N3的大部分產能,未來還會佔據N2的大部分產能。那有沒有一種可能,你們會回到更舊的製程,比如7nm,利用那些「閒置產能」,重新做類似Hopper或者Ampere這樣的架構,但結合今天在數值計算、系統設計等方面的進步。你覺得這種情況,會不會在2030年前發生?
黃仁勳:沒有必要這樣做。因爲每一代架構的進步,不只是晶體管規模。它還包括大量工程優化、封裝、堆疊、數值計算(numerics)、系統架構等等,如果你想回到舊制程,那意味着你要重新做一整套研發。這是一個幾乎沒有人負擔得起的研發成本。
我們可以向前推進,但我不認爲我們能向後回退。當然,如果我們做一個思想實驗:如果有一天,世界真的說「我們再也不會有更多先進產能了」,那我會不會立刻用7nm?當然會。毫不猶豫。
Dwarkesh:還有一個問題,是別人問我的。爲什麼英偉達不同時做多個完全不同的芯片項目?比如類似Cerebras那種超大芯片、類似TeslaDojo那樣的系統,甚至做一個完全不依賴CUDA的架構。你們有資源、有工程能力,爲什麼不把賭注分散?畢竟AI未來的架構方向還不確定。
黃仁勳:我們當然可以這麼做。只是我們沒有看到一個更好的方案。這些東西我們都在仿真系統裏模擬過,它們的效果其實更差。所以我們不會去做。我們現在做的,就是我們認爲最正確的架構。
當然,如果未來工作負載本身發生變化——我說的不是算法變化,而是工作負載的形態變化,那我們可能會增加新的加速器。比如最近,我們引入了Grok相關的方向,並且會把它整合進CUDA生態。
這是因爲Token的價值變高了。幾年前,Token幾乎是免費的,或者非常便宜。但現在不一樣了,現在不同客戶對Token有不同需求。比如,如果我是軟件工程師,我願意爲更快響應的Token付錢,因爲它能讓我更高效。這個市場是最近才出現的。
所以我們現在可以做一件事:同一個模型根據響應時間,劃分出不同市場。這也是爲什麼我們決定擴展推理的「帕累託前沿」(Pareto frontier)做一個響應更快、但吞吐更低的推理形態。
過去大家都認爲吞吐越高越好,但現在可能出現一種市場:Token價格很高(ASP高),即使吞吐低,整體收益仍然更高。如果是這樣那我們就會去做。但從架構角度來說,如果我有更多資源,我更願意把它投入到現有架構上,而不是分散。
Dwarkesh:這個高價Token市場的想法非常有意思。
黃仁勳:是的,本質是市場分層(segmentation)。
Dwarkesh:最後一個問題。假設深度學習革命沒有發生,英偉達今天會在做什麼?
黃仁勳:還是同一件事:加速計算。我們公司的基本假設一直是,摩爾定律會放緩,通用計算不會適用於所有問題。所以我們把GPU和CPU結合,讓GPU去加速特定計算。
不同的算法、不同的kernel,可以被卸載到GPU上執行,從而讓應用加速100倍、200倍。這些應用在幾乎所有地方:科學計算、工程、物理、數據處理、圖形計算、圖像生成……即使沒有AI,英偉達也會是一個非常大的公司。
因爲這是一個更基礎的問題,通用計算的擴展已經接近極限,而解決方案就是領域專用加速(domain-specific acceleration)。我們從圖形開始,但其實有無數其他領域,像分子動力學、地震數據處理、能源勘探、圖像處理……這些都是通用計算無法高效解決的問題。我們的使命一直是把加速計算帶給世界,推動那些通用計算無法突破的領域。
當然,如果沒有AI,我會很難過。但正是因爲我們在計算上的這些進展,讓深度學習更加普及,讓任何人都可以用一張GPU卡做出很厲害的事情。這一點,從來沒有改變。
如果你去看GTC,前面很大一部分內容其實都不是AI。比如計算光刻、量子化學、數據處理,這些都是非常重要的工作,只是沒有AI那麼火。
世界上有很多重要的事情並不依賴AI,而Tensor也不是唯一的計算方式。我們希望幫助所有人。
編輯/rice