
圍繞AI算力基礎設施的價值鏈的權重分佈也開始邁向轉變態勢,下一輪超額阿爾法收益將不再只屬於AI GPU/AI ASIC領域最強龍頭名單,而會系統性擴散到CPU、存儲、PCB、液冷系統、ABF載板與廣泛晶圓代工等全棧AI算力基礎設施層。
週五美股盤初,兩大x86架構CPU超級巨頭—— $英特爾 (INTC.US)$ 與 $美國超微公司 (AMD.US)$ 股價攜手創下歷史新高點位,開創x86架構的美國老牌芯片巨頭英特爾股價在強勁超預期的業績支撐之下,更是一度瘋漲超過27%。
另一聚焦高性能x86架構的AI數據中心服務器CPU的芯片行業霸主AMD股價也不甘示弱,開盤股價即瘋漲超過14%一舉創下歷史新高。
 ARM指令集架構擁有者 $Arm Holdings (ARM.US)$ 股價同樣漲勢如虹, 開盤股價即創下歷史新高,凸顯出具備高能效和低功耗方面巨大優勢的ARM架構同樣備受投資者青睞。
ARM指令集架構擁有者 $Arm Holdings (ARM.US)$ 股價同樣漲勢如虹, 開盤股價即創下歷史新高,凸顯出具備高能效和低功耗方面巨大優勢的ARM架構同樣備受投資者青睞。
隨着Anthropic重磅推出的Claude Cowork,以及OpenClaw這類可自主執行任務的超級AI代理工具在2026年集中爆發,這一股AI智能體(AI Agent)浪潮迅速席捲全球,AI算力架構瓶頸可謂正在從以矩陣乘加吞吐爲核心的GPU,徹底轉向以控制流、任務編排、內存/IO協調爲核心的數據中心CPU,面向超大規模AI數據中心的高性能CPU陷入嚴峻供不應求態勢。
過去兩年AI敘事幾乎被GPU壟斷,CPU一度像是AI軍備競賽裏的「配角」;但隨着開源的OpenClaw這類型代理式AI工作流(即AI智能體)主導的推理工作負載、數據編排、任務調度、內存訪問、網絡通信和多工具調用全面增長,市場可謂徹底意識到:沒有強大的CPU作爲系統中樞,GPU集群無法高效運轉。這本質上就是CPU從「被低估的基礎設施」重新回到AI數據中心核心舞臺,帶有非常明顯的「文藝復興」式復古浪潮意味。
進入AI智能體時代之後,算力體系開始從單純堆GPU,轉向更復雜的異構計算:CPU要承擔任務大規模調度、數據搬運、內存管理、模型調用、工具鏈編排、推理請求分發、數據庫檢索、網絡通信和安全隔離。換句話說,CPU不再只是AI數據中心裏的「背景零件」,而是重新成爲AI工廠的系統中樞與調度大腦。這正好對應「文藝復興」的核心意象:一個曾被市場低估、被GPU光環遮蔽的傳統算力架構,重新獲得時代價值和資本市場定價權。
AI數據中心建設進程如火如荼可謂推動英特爾數據中心CPU陷入供不應求態勢,英特爾部分需求最火熱的高性能服務器CPU交期最長拉到足足6個月之久,面向數據中心的這些高性能服務器級別CPU價格今年以來則普遍上漲10%。這也是爲何股價萎靡1年半之久的芯片製造商英特爾股價能夠在今年暴漲超120%且一舉創下歷史新高。
GPU不再獨霸算力主題,智能體浪潮引爆CPU
摩根士丹利、Stifel 、DA Davidson等華爾街金融巨頭們認爲兩大PC與數據中心CPU巨頭——英特爾和AMD處於從數據中心CPU需求創紀錄級別大爆發中受益的最有利核心位置;此外,華爾街頂級分析師們認爲存儲芯片巨頭們也將受益於CPU需求指數級擴張態勢,摩根士丹利認爲美國大型存儲廠商 $美光科技 (MU.US)$ 以及 $閃迪 (SNDK.US)$ 同樣處於最佳位置。
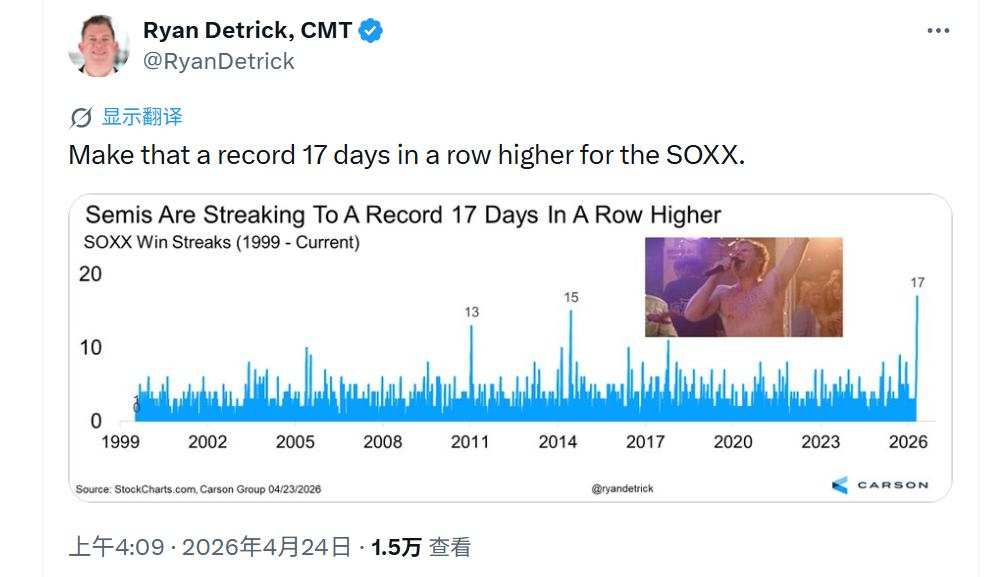
隨着韓國股市基準——三星( $南方兩倍做多三星電子 (07747.HK)$ )與SK海力士 ($南方兩倍做多海力士 (07709.HK)$ )佔據高額權重的 $韓國綜合指數 (.KOSPI.KR)$ 在地緣政治局勢惡化重壓之下創下歷史新高,以及AI熱潮最大贏家之一——有着「芯片代工之王」稱號的權重股 $台積電 (TSM.US)$ 帶動之下中國臺灣股市也創下歷史新高,加之有着「芯片股風向標」稱號的 $費城半導體指數 (.SOX.US)$ 出現創紀錄的17連漲,都令投資者們愈發堅信「AI算力投資主題」能夠壓倒一切市場噪音。
與此同時,圍繞AI算力基礎設施的價值鏈的權重分佈也開始邁向轉變態勢,下一輪超額阿爾法收益將不再只屬於AI GPU/AI ASIC領域最強龍頭名單,而會系統性擴散到CPU、存儲、PCB、液冷系統、ABF載板與廣泛晶圓代工等全棧AI算力基礎設施層,而在這輪主線敘事切換中,大摩等華爾街金融巨頭認爲面向數據中心的CPU與DRAM/NAND存儲芯片可能是最核心受益的AI算力細分類別。
在智能體鏈路中,大量工作負載不僅耗費在GPU上的token生成,還消耗在Python解釋執行、網頁抓取、數據庫檢索、RAG索引訪問、詞法處理、任務隊列調度、RPC/IPC通信、KV狀態更新等CPU主導環節,這意味着決定用戶體驗的,越來越不是單顆GPU的峰值算力,而是CPU是否有足夠的核心數、線程併發、緩存層級、內存帶寬、PCIe/CXL/互連調度能力去支撐高頻工具調用與高密度任務切換。一旦CPU核心、內存子系統或I/O調度不足,GPU即便名義算力充裕,也會因數據準備、任務協調和系統等待而出現利用率塌陷。
因此,毋庸置疑的是,AI算力架構的瓶頸正在從以矩陣乘加吞吐爲核心的GPU,徹底轉向以控制流、任務編排、內存/IO協調爲核心的數據中心CPU,這一變化的根源在於工作負載範式已經發生了本質遷移。CPU不再只是通用計算芯片,而是智能體時代的控制平面處理器、系統編排引擎與資源調度中樞,「被低估的CPU成爲AI新瓶頸」並非情緒化判斷,而是AI工作負載從「推理計算問題」進一步升級爲「複雜系統工程問題」後的必然結果。
早期大模型推理以「單次請求—單次生成」爲主,CPU更多承擔數據搬運、請求路由與基礎調度,屬於典型的輔助控制面;但進入AI智能體與強化學習時代後,系統負載不再是單一前向推理,而是演變爲包含任務規劃、工具調用、子代理協同、環境交互、狀態管理與結果驗證在內的複雜閉環。上述「編排層」(orchestration layer)本質上是強控制流、強分支判斷、強系統調用、強內存訪問的CPU密集型任務,無法被GPU高效替代,因此CPU正從過去的「配角」變成決定系統吞吐、時延與資源利用率的新瓶頸。
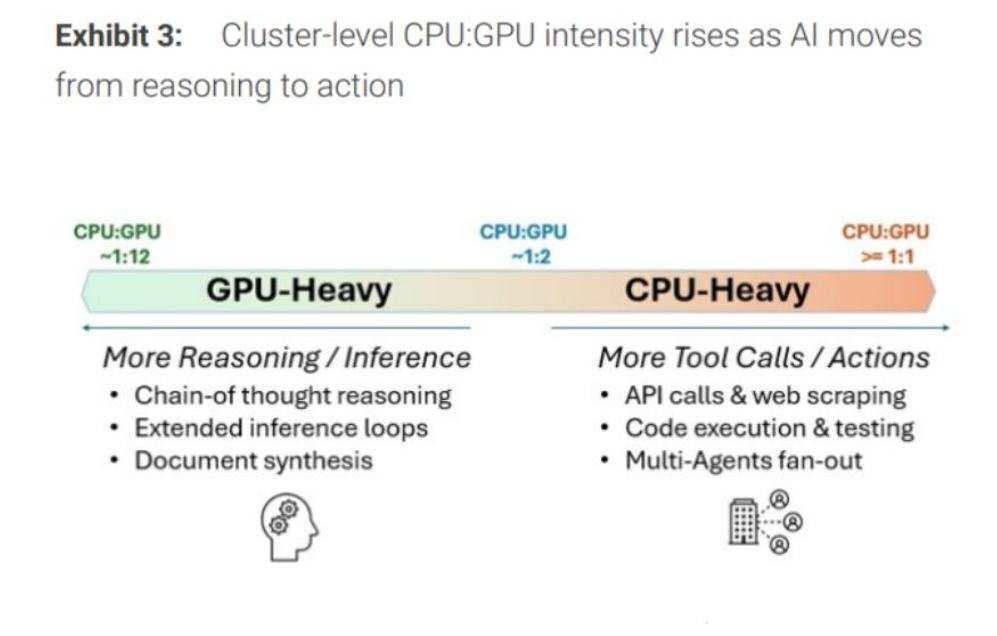
摩根士丹利最新預測數據顯示,智能體大爆發標誌着從計算到編排的結構性轉變,由此推導出到2030年新增325億美元至600億美元的CPU增量市場空間,並將服務器級別CPU總TAM大幅擴至825億至1100億美元量級。TrendForce的一項預測報告則顯示,在AI智能體時代,CPU:GPU配比可能會從傳統AI數據中心的1:4至1:8,向1:1至1:2大幅重估。
華爾街高呼AMD以及ARM漲勢未完結
截至發稿,英特爾股價徘徊於85美元附近,日內最高漲幅超過27%,已經超過華爾街絕大多數分析師們的樂觀目標股價,但是AMD與ARM公司距離華爾街最高目標股價仍有一段距離。
由華爾街資深策略師Joseph Moore領銜的摩根士丹利分析師在近日發佈的一份投資者報告中表示:「CPU走強帶來的顯而易見受益者——英特爾和AMD——在一定程度上策略框架較爲複雜,但是服務器CPU需求指數級擴張對於對兩者的盈利前景都至關重要。」
“在兩者之間,我們更偏好AMD;另外,在當前時點,我們認爲存儲芯片廠商們具有顯著更優的風險回報比,存儲主題可謂是CPU需求擴張的直接受益者之一。”Joseph Moore領銜的摩根士丹利分析師們表示。
華爾街資深分析師分析師Gil Luria領導的D.A. Davidson團隊在英特爾公佈強勁業績報告之後,選擇在週五美股盤前上調AMD(AMD.US)股票評級,並且大舉上調未來12個月目標價至375美元——位列華爾街最高目標股價。
「我們將AMD股票評級從中性上調至買入,並將目標價從220美元上調至375美元,依據是CPU需求出現結構性增長,同時AMD在這場偉大數據中心建設浪潮中的角色能見度大幅改善。我們認爲,鑑於英特爾業績超預期的幅度,AMD的業績預期存在顯著上行空間,這將從AMD定於5月5日公佈的3月季度業績開始體現。」Gil Luria領導的D.A. Davidson團隊表示。
「我們認爲,英特爾的業績是AMD CPU業務將迎來巨大躍升的前奏,並相信向代理式AI工作負載的結構性轉變,正在爲服務器CPU創造前所未有的需求。我們認爲,鑑於我們判斷在可預見的未來需求將超過供給,AMD處於有利位置,可以在整個產品組合中大幅提價,以支撐並擴大利潤率。」Gil Luria領導的D.A. Davidson團隊補充表示。
華爾街當前對ARM的看漲邏輯方面,核心邏輯已經從「智能手機IP授權公司」切換爲AI數據中心CPU與Agentic AI基礎設施超級浪潮的核心受益者之一。最高目標價方面,華爾街知名投資機構Guggenheim近日將ARM目標股價上調至華爾街最高位的240美元,看多理由是ARM公司正從傳統的智能手機與移動端輕量級消費電子設備IP授權方,轉向AI數據中心硅片與超級計算平台的直接參與者。
據了解,週五公佈的一項最新聲明顯示,美國雲計算與電商巨頭 $亞馬遜 (AMZN.US)$ 與Facebook母公司 $Meta Platforms (META.US)$ 已達成一項數十億美元的長期協議,這家社交媒體巨頭將租用數十萬顆亞馬遜自研推出的ARM架構通用數據中心服務器CPU芯片,用於其正在大規模新建的AI數據中心,以滿足Facebook以及Instagram等社交媒體用戶們的天量級別人工智能推理端工作負載。
Graviton是亞馬遜旗下AWS雲計算業務部門自研的ARM架構通用服務器CPU,主要承擔AI數據中心裏的通用計算、調度、數據預處理/後處理、服務編排,以及部分AI推理相關調度與協調工作。
對Meta這種每天處理海量AI agent、推薦、廣告、內容生成和查詢響應的公司來說,很多任務並不需要昂貴GPU全程參與;大規模利用Graviton這類高密度ARM架構而非英特爾x86架構CPU承接推理服務外圍負載,可以降低單位請求成本、釋放GPU給更高價值的訓練/推理任務,並改善整體集群TCO。Arm公司也強調,AI數據中心擴張正在讓低功耗、高效率的ARM架構CPU側的編排、數據處理和系統控制成爲關鍵瓶頸,而AWS第五代Graviton把核心數提升到192核,反映的正是這種CPU密度需求上升。
Arm堪稱全球人工智能狂熱浪潮最大贏家之一,英偉達自研的Grace CPU正是基於ARM架構,亞馬遜的自研數據中心Graviton服務器處理器同樣採用ARM架構,類似的還有基於基於ARM Neoverse所打造的Google Axion Processors這一谷歌第一代自研ARM架構數據中心CPU,以及微軟Azure Cobalt 100自研ARM架構數據中心CPU,ARM架構可謂正在從「智能手機之王」演變成AI雲時代的算力基礎設施底座之一。
ARM所採用的精簡指令集計算架構使得基於其設計的服務器CPU在執行AI推理/訓練任務時,相比於英特爾x86架構,具備高能效和低功耗方面的巨大優勢。這一特性使得ARM架構特別適合用於數據中心服務器領域,能夠高效配合AI GPU來滿足幾乎無止境的AI推理/訓練算力需求。
編輯/KOKO