
谷歌發佈開源實驗性模型DiffusionGemma,顛覆傳統逐詞生成邏輯,每次前向傳播並行生成256個詞元,在H100上實測突破每秒1000詞元,最高實現四倍提速。該模型僅激活3.8B參數,量化後可跑在18GB顯存消費級顯卡上,爲開發者在低延遲本地工作流場景中提供了新的技術路徑。
谷歌發佈開源實驗性模型DiffusionGemma,採用文本擴散技術,在專用GPU上實現最高四倍的文本生成加速,爲開發者在低延遲本地工作流場景中提供了新的技術路徑。
這一模型基於谷歌Gemma 4系列架構與Gemini Diffusion研究成果構建,以Apache 2.0許可證開源發佈。
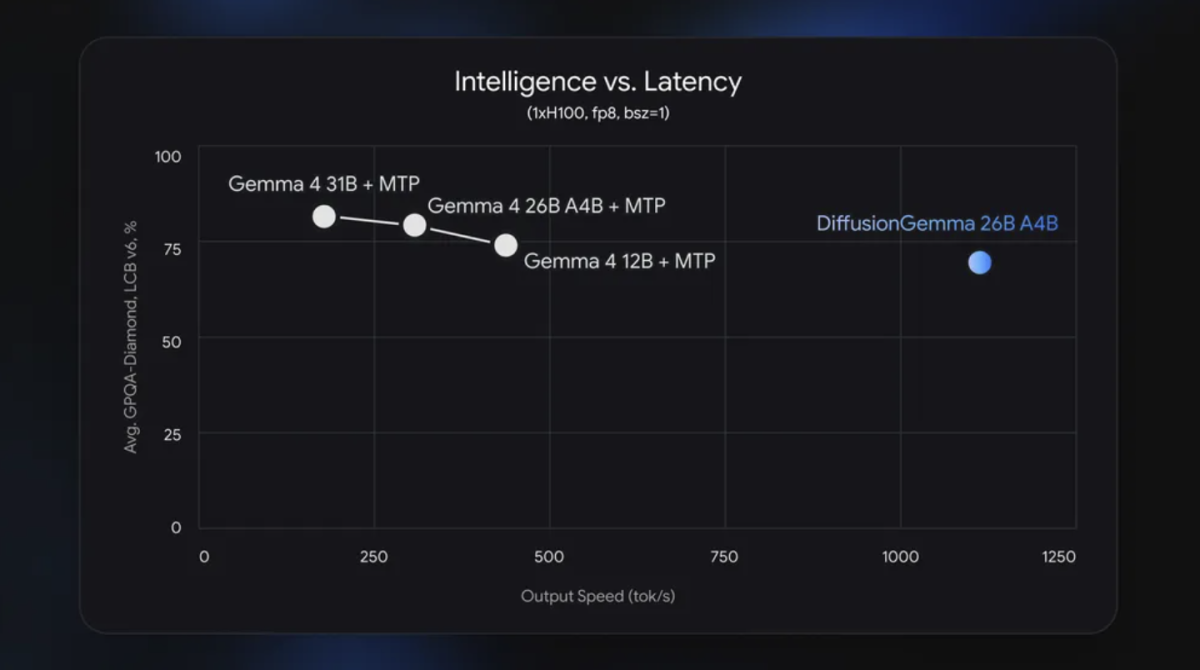
 與傳統自回歸大語言模型逐詞生成的方式不同,DiffusionGemma每次前向傳播可並行生成256個詞元,在單張NVIDIA H100上實測輸出速度超過每秒1000個詞元,在NVIDIA GeForce RTX 5090上則超過每秒700個詞元。
與傳統自回歸大語言模型逐詞生成的方式不同,DiffusionGemma每次前向傳播可並行生成256個詞元,在單張NVIDIA H100上實測輸出速度超過每秒1000個詞元,在NVIDIA GeForce RTX 5090上則超過每秒700個詞元。
谷歌同時指出,DiffusionGemma目前仍處於實驗階段,整體輸出質量低於標準Gemma 4模型。對於追求最高質量輸出的生產應用,谷歌建議繼續部署標準Gemma 4。
架構創新:從"打字機"到"印刷機"
DiffusionGemma的核心技術突破在於改變了語言模型使用硬件的方式。
傳統語言模型如同打字機,從左至右逐詞生成文本。這一機制在雲端服務器上效率尚可,因爲服務器可將數千條用戶請求批量處理、共享算力。但當模型在單用戶本地環境中運行時,逐詞生成的方式使GPU大部分時間處於等待狀態,算力嚴重閒置。
DiffusionGemma採用文本擴散方法,將上述瓶頸從內存帶寬轉移至計算側。
模型首先在"畫布"上生成一組隨機佔位詞元,隨後進行多輪迭代精煉——在每一輪中鎖定已確認的詞元,並以其爲上下文線索修正其餘內容,最終收斂爲完整段落輸出。谷歌將這一過程比喻爲"將單台打字機升級爲同時印刷整頁文字的大型印刷機"。
值得注意的是,這一速度優勢具有明確的適用邊界。谷歌表示,在高併發雲端服務場景中,自回歸模型可通過批量處理充分利用算力,DiffusionGemma的並行解碼優勢遞減,反而可能推高服務成本。其吞吐量優勢主要體現在單張加速器上的低至中等批次規模場景。
低硬件部署門檻,支持雙向注意力與自糾錯
DiffusionGemma爲26B參數的混合專家(MoE)模型,但推理時僅激活3.8B參數。經量化處理後,模型可在18GB顯存的消費級高端GPU內運行,降低了本地部署的硬件門檻。
在功能特性上,模型支持雙向注意力機制,每個詞元在生成時可關注段落內所有其他詞元。谷歌認爲這一特性在非線性生成任務中具有明顯優勢,具體包括行內編輯、代碼填充、氨基酸序列生成及數學圖形構建等場景。
模型還具備智能自糾錯能力,可在輸出過程中對整段文本進行實時評估和修正。
第三方AI工具公司Unsloth對DiffusionGemma進行了微調,成功使其完成數獨求解任務——這類需要前瞻推理的問題對傳統自回歸模型構成挑戰,而DiffusionGemma的雙向注意力機制使其處理此類任務更爲自然。

定位與侷限:實驗探索而非生產替代
谷歌明確將DiffusionGemma定位於研究人員和開發者,而非直接替代現有生產模型。其目標用例集中於對速度敏感的本地交互工作流,例如文本實時編輯、快速內容迭代以及非線性文本結構生成。
儘管速度優勢顯著,但谷歌坦承DiffusionGemma在輸出質量上仍遜於標準Gemma 4,並在基準測試中呈現出明確的能力取捨關係。這意味着對於需要高精度輸出的商業應用,該模型目前尚不具備替代現有主流模型的條件。
文本擴散技術本身並非新概念,AI研究界已探索多年,但將其應用於大規模模型長期面臨挑戰。
DiffusionGemma的發佈標誌着谷歌在將這一研究方向推向實用化方面邁出了可量化的一步,其後續能否在質量與速度之間取得更優平衡,將是市場持續關注的焦點。
編輯/Liam