
①在Artificial Analysis綜合榜單上,GLM-5.2取得51分,位列開源模型SOTA;②預計下半年昇騰950超節點上市後,將成爲GLM-5.2重要的算力底座。
《科創板日報》6月17日訊(記者 李明明)6月17日,智譜發佈並開源新一代旗艦大模型GLM-5.2。
在Artificial Analysis綜合榜單上,GLM-5.2取得51分,位列開源模型SOTA。
 據智譜方面向《科創板日報》記者介紹,這是其迄今能力最強的開源模型,核心只做了兩件事:即把1M token上下文從「紙面參數」做成「生產可用」;同時把長程Coding能力再往前推了一步。
據智譜方面向《科創板日報》記者介紹,這是其迄今能力最強的開源模型,核心只做了兩件事:即把1M token上下文從「紙面參數」做成「生產可用」;同時把長程Coding能力再往前推了一步。
《科創板日報》記者第一時間對GLM-5.2 Max進行了數小時連續實測,任務覆蓋長上下文檢索與生成、Long Horizon長程Agent編碼,一次性完成近百萬token複合型行業調研全鏈路交付等場景。
實測GLM-5.2
據智譜方面介紹,GLM-5.2的核心突破在於將百萬級上下文窗口做到了工程可用 。
例如,模型可在一輪連續任務中處理88萬以上token,自主完成從開發、聯調、測試到打包上線的完整軟件交付流程,數小時內產出一個覆蓋網頁端、移動端與小程序的完整應用。而在過去,類似體量的工程通常需要一支團隊協作數週。
目前市面上支持百萬級上下文的模型並不少,但一個公開的祕密是很多模型在30萬token之後就開始"丟信息",長文本下的推理質量呈斷崖式下跌。智譜的技術方案是一組注意力結構層面的創新:KV8量化、LayerSplit、IndexShare 4和HiSparse稀疏注意力機制的組合。
從工程角度看,這組改動的目標很明確:在1M長度下同時壓低效果衰減和推理成本。智譜官方數據顯示,在1M上下文長度下,單位token的FLOPs降低至2.9倍(即相比傳統方案減少了約66%的計算量)。
智譜在技術博客中披露了該模型的一個實測結果:模型一次性完成了覆蓋Web、移動端與小程序的完整應用開發交付,累計處理88萬tokens,幾乎用滿1M窗口。這意味着在真實的超長工程任務中,模型能夠完整保持項目狀態,而不是在第十輪對話後就忘了第三輪定下的約束。
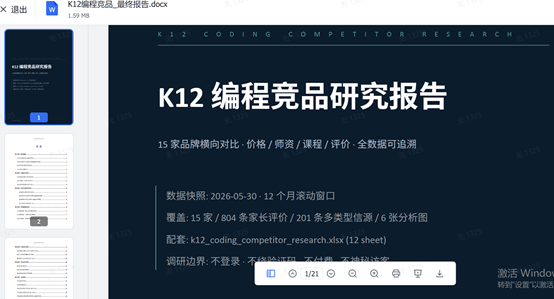
《科創板日報》記者也實測了GLM-5.2,實測任務要求模型基於海量公開素材完成K12在線編程教育競品深度調研,橫向覆蓋15家賽道主流品牌,拆解課程、師資、定價、家長評價四大核心維度,一次性交付帶溯源索引的XLSX數據庫、20頁PDF完整分析報告、6張可視化對比圖表、可複用數據處理腳本全套成果。
經過半小時左右,最終模型完整留存804條家長評價,輸出含12個數據分表的標準化Excel、完整行業報告、可運行腳本,全程未出現品牌混淆、數據維度丟失、統計口徑錯亂等長文本模型常見問題。但1M上下文的極端場景仍有優化空間。

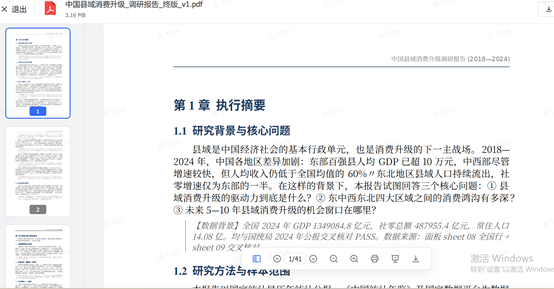
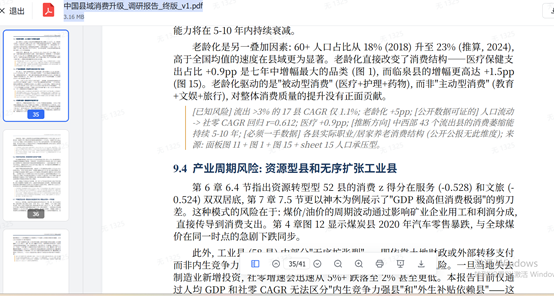
爲了進一步驗證模型的深度分析研究能力,《科創板日報》記者又下了一個實測指令:基於國家統計局及可公開覈驗的宏觀數據,對 2018-2024 年中國縣域消費升級開展系統化研究,構建覆蓋 200+ 縣域的可溯源數據庫,並交付數據底表、研究報告、彙報 PPT 及配套可視化圖表。
實測發現, GLM-5.2 Max可單輪承載近百萬宏觀統計素材,一次性完成全國四百餘縣域量化數據庫搭建、深度分析報告與成套可視化圖表全鏈路交付,適配金融諮詢級長週期大數據研究任務。
那麼,如何將GLM-5.2的編程能力放在全球最頭部模型中進行定位?
北京計算機學會AI專委會秘書長、北京大學特聘研究員張有魚告訴《科創板日報》記者,智譜GLM-5.2的發佈標誌着國產模型在編程細分場景取得了關鍵性突破。
首先,打破雙寡頭壟斷,依託登頂全球編程基準的實測表現與高性價比,GLM-5.2在長上下文編程場景下優勢顯著,正在重塑行業格局,催生智譜、OpenAI、Anthropic三方鼎立的「新御三家」。
其次,雖未能實現全維度超越,但在目前多數中高頻的實際開發場景下,該模型已完全可以作爲海外頭部模型的替代方案。「但是核心短板仍存,在深度的數理邏輯推理與跨領域知識的複雜融合上,GLM-5.2與海外最頂尖水平相比仍存在一定的技術代差,這是下一步需要重點攻堅的方向。」
國產算力Day 0適配
在性能之外,GLM-5.2以最寬鬆的 MIT 協議開放,允許免費商用,且模型訓練與線上推理均未依賴海外算力。
上線首日,GLM-5.2的線上推理已在Day 0完成與八大國產算力平台的推理適配。這一「開源國模 + 國產算力」的組合受到行業關注。
智譜方面同時對《科創板日報》記者表示,預計下半年昇騰950超節點上市後,將成爲GLM-5.2重要的算力底座。
"Day 0適配"不是指模型"能在國產芯片上跑起來",而是意味着在發佈當天就已經完成了深度推理適配與算子級優化——這代表國產芯片不是作爲"備胎"存在,而是與海外算力平台同等對待的第一梯隊底座。
智譜的適配名單覆蓋了國產算力的頭部企業:華爲昇騰、寒武紀、摩爾線程、海光、壁仞、沐曦、崑崙芯、平頭哥。既是爲了分散供應鏈風險,也是爲了最大化觸達不同行業的國產化替代需求。
從商業邏輯來看,當前,國內大模型公司的算力成本中,GPU採購和租賃佔據了大頭,且高度依賴英偉達H100/H200等海外高端芯片。而在中美科技博弈持續升級的背景下,算力供應鏈的自主可控已經從"戰略儲備"變成了"生存必需"。
從開發者視角看,國產算力適配意味着兩件事:一是企業用戶可以在純國產環境中私有化部署GLM-5.2,滿足數據安全和合規要求;二是當海外算力供應出現波動時,國產替代方案已經準備完善,不需要從頭開始適配。
從技術角度看,在多個架構差異顯著的國產芯片上完成推理適配,要求模型在算子兼容性、內存管理和推理效率方面做大量工程調優。智譜能夠做到Day 0同步適配,表明其底層工程團隊在異構計算方面已有較深積累。